Appearance
Agilor数据采集系统
开发语言
Agilor 数据采集系统主要是采用Go编程语言开发完成的。Go 语言具有很强的表达能力,它简洁、清晰而高效。主要得益于其并发机制, 用它编写的程序能够非常有效地利用多核与联网的计算机,其新颖的类型系统则使程序结构变得灵活而模块化。Agilor 数据采集系统正是借助Go的并发机制和有效的利用 CPU 的多核特性,提高整体系统的执行效率和实时性;通过灵活的模块化管理,实现不同采集接口的挂载。
运行环境与依赖
Agilor 数据采集系统V6目前支持Windows、Linux、Darwin内核系统,支持x86、ARM、RISC-V处理器架构。对国产软硬件支持如下:
- 银河麒麟高级服务器操作系统(兆芯版)V10
- 银河麒麟高级服务器操作系统(海光版)V10
- 银河麒麟高级服务器操作系统(AMD64版)V10
- 统信服务器操作系统V20(海光7000处理器)
- 统信服务器操作系统V20(ZX-C+、KH-20000、KH-30000)
- 方德高可信服务器系统 V4.0
- 龙芯3B4000平台
注:OPC DA 与 PI 系统接口目前只能运行在 Windows 环境。
系统架构
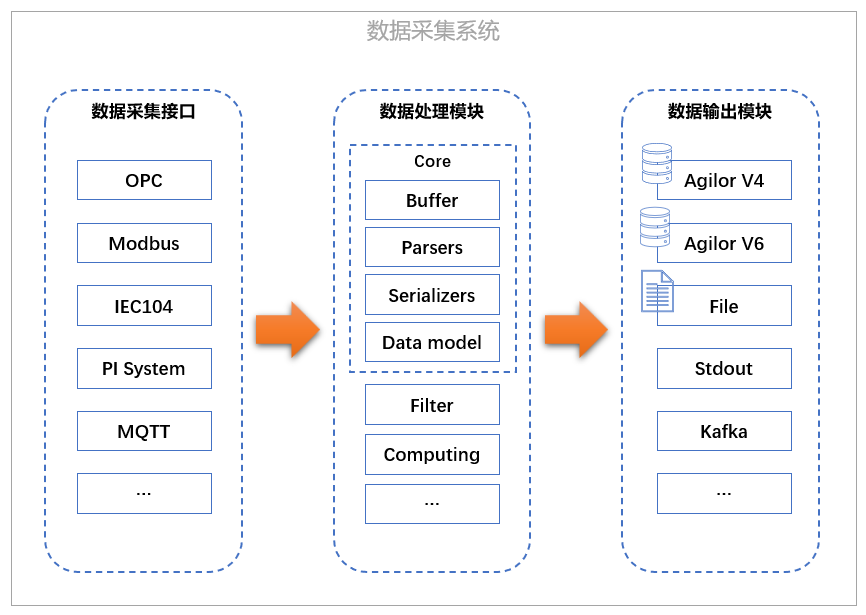
如上图所示,数据采集系统借鉴ETL(Extract-Transform-Load)设计理念,将工业设备数据或物联网数据的原始数据经过提取(数据采集接口)、转换(数据处理模块)、加载(数据输出模块)到Agilor数据库或其他存储形式中的过程,其核心是把多种不同的数据抽象出来,形成统一的数据模型(Data Model)先放入缓存区中,等待进一步数据处理,最后把结果输出到指定输出模块,如Agilor 实时数据库中。
数据采集接口
数据采集接口是解决的是数据来源问题 。主要有以下几种:
设备数据
在工业生产环境中,需要对实时对流水线数据进行监控预警,如锅炉温度采集预警、燃气计量阀、点表用量等等,这些数据一般都是通过Modbus协议或TCP协议进行传输,或统一汇集到OPC或MQTT进行访问,对这些协议和接口的支持是我们获取数据的一个重要来源。
第三方数据接入
通过第三方数据入的数据,这些数据可以作为我们业务分析和历史数据的补充数据。这些数据一般采用第三方数据接口(API)形式,把数据传输过来。第三方的来源、数据形式格式可能有多种多样,就需要我们分别进行对接处理。如目前已经支持的 PI Server。
通过以上不同的接口协议将采集到的数据写入实时数据库中,现有标准接口数据采集已广泛应用于生产环境,对于非标准接口数据采集,可根据用户要求定制开发。
数据处理模块
数据处理模块主要分为核心模块和数据处理模块,核心模块主要包括:
数据缓存(Buffer):主要是暂存即将处理的数据,缓存的大小可根据用户的业务数据量决定,对于数据比缓存大情况下,将采用FIFO缓存淘汰算法 解析器(Parsers):主要是根据业务数据自动适配或手动分配解析接口,如对于Modbus协议可根据设备支持程度通过RTU或ASCII方式进行解析数据 序列化(Serializers):主是将处理的数据按指定模型进行输出,如写入到Agilor v4和写入到Agilor v6 将采用不同的序列化模型 数据模型(Data model):主要是将不同的数据转换成统一的数据模型进行处理
另一部分,根据我们的业务需求,可以采用一些规则、方法进行数据处理。一般常见的数据处理模型操作有:
筛选:筛选部分数据,或者部分字段,提取一部分有用的数据或过滤掉无用的数据 格式转换:如数字量类型转换,把OFF转成1,ON转成1 计算:如原数据中的温度为整形,需要通过设备厂家的计算公式计算出正常识别的摄氏度
数据输出模块
数据输出模块主要是周期性将缓存数据输出到指定的子模块中,比如对实时性要求比较高的,可采用秒级数据写入;对数据比较大的,可以成批写入;对于输出不稳定的子模块,还可进行多次尝试输出,而尝试次数和间隔可通过用户配置,也可以通过指数退避算法(Exponential backoff)避免过于频繁的访问服务器。
关键技术
Agilor实时数据采集中,保证数据的采集的实时性(毫秒级)
缓存淘汰机制,根据实时数据的特点, FIFO 缓存淘汰算法,保留最新的数据
避免过量和服务器进行通讯,采用指数退避算法(Exponential backoff)